
Bard, Google’s beleaguered AI-powered chatbot, is slowly improving at tasks involving logic and reasoning. That’s according to a blog post published today by the tech giant, which suggests that — thanks to a technique called “implicit code execution” — Bard is now improved specifically in the areas of math and coding.
As the blog post explains, large language models (LLMs) such as Bard are essentially prediction engines. When given a prompt, they generate a response by anticipating what words are likely to come next in a sentence. That makes them exceptionally good email and essay writers, but somewhat error-prone software developers.
But wait, you might say — what about code-generating models like GitHub’s Copilot and Amazon’s CodeWhisperer? Well, those aren’t general-purpose. Unlike Bard and rivals along the lines of ChatGPT, which were trained using a vast range of text samples from the web, ebooks and other resources, Copilot, CodeWhisperer and comparable code-generating models were trained and fine-tuned almost exclusively on code samples.
Motivated to address the coding and mathematics shortcomings in general LLMs, Google developed implicit code execution, which allows Bard to write and execute its own code. The latest version of Bard identifies prompts that might benefit from logical code, writes the code “under the hood,” tests it and uses the result to generate an ostensibly more accurate response.
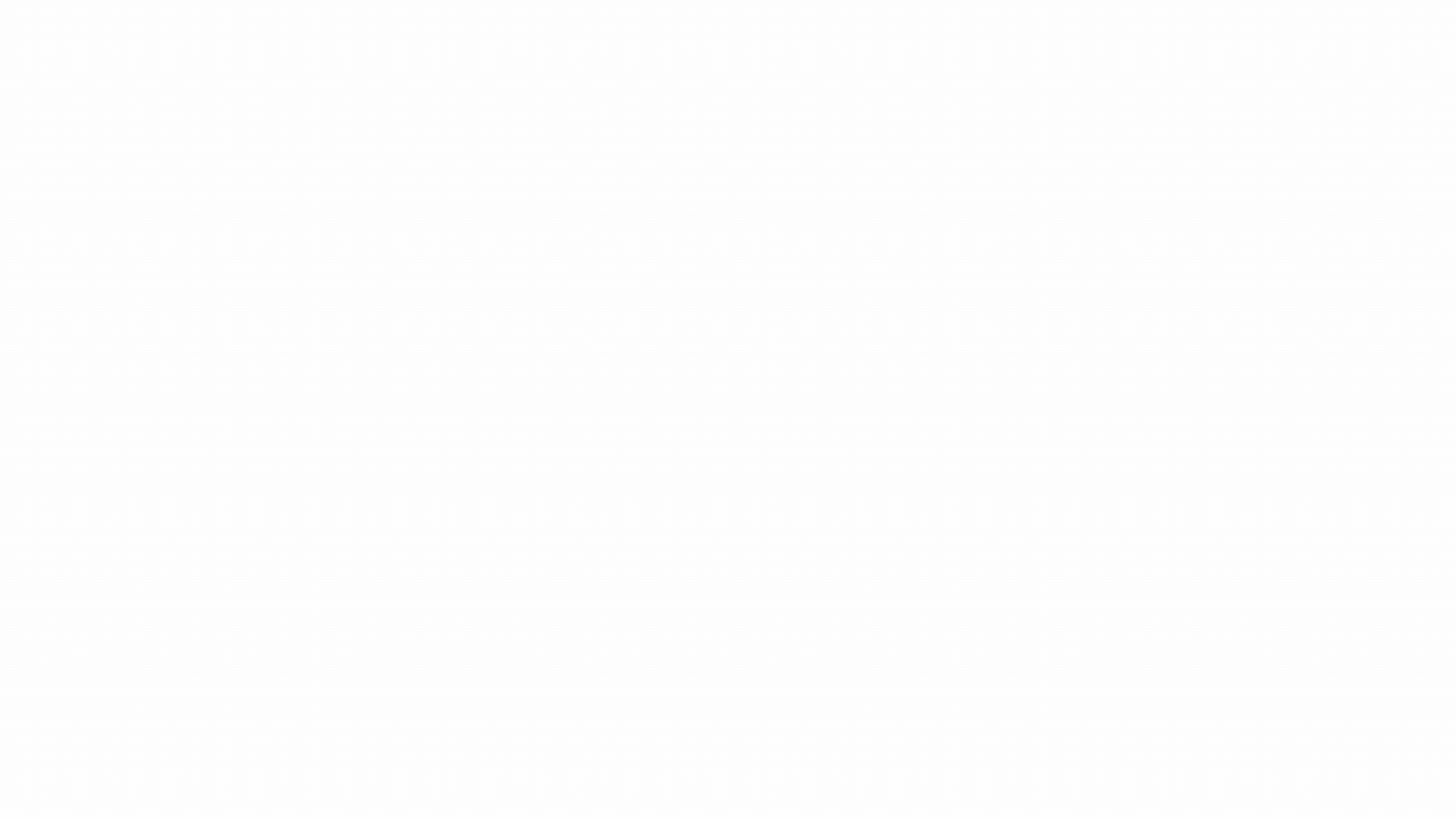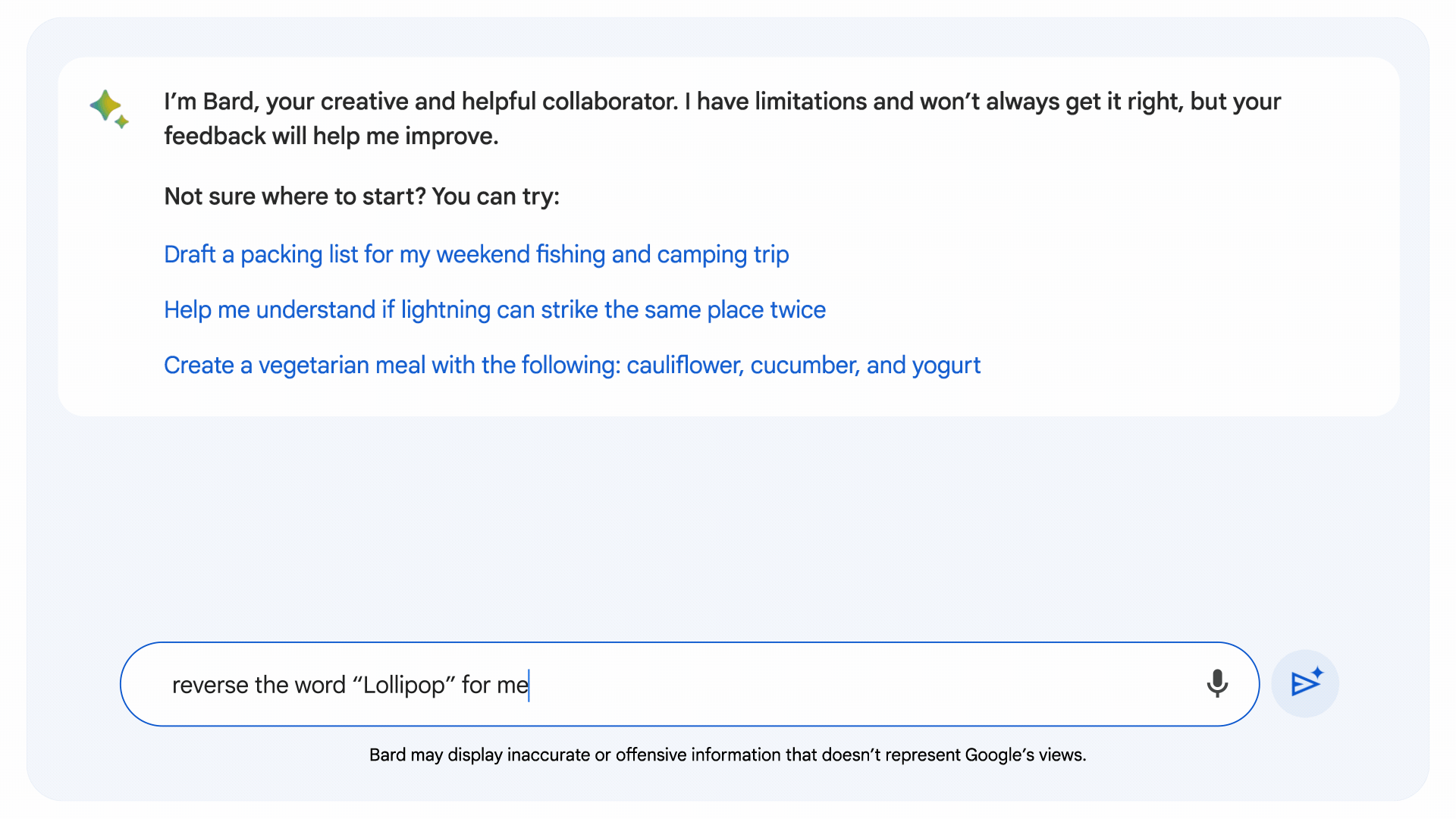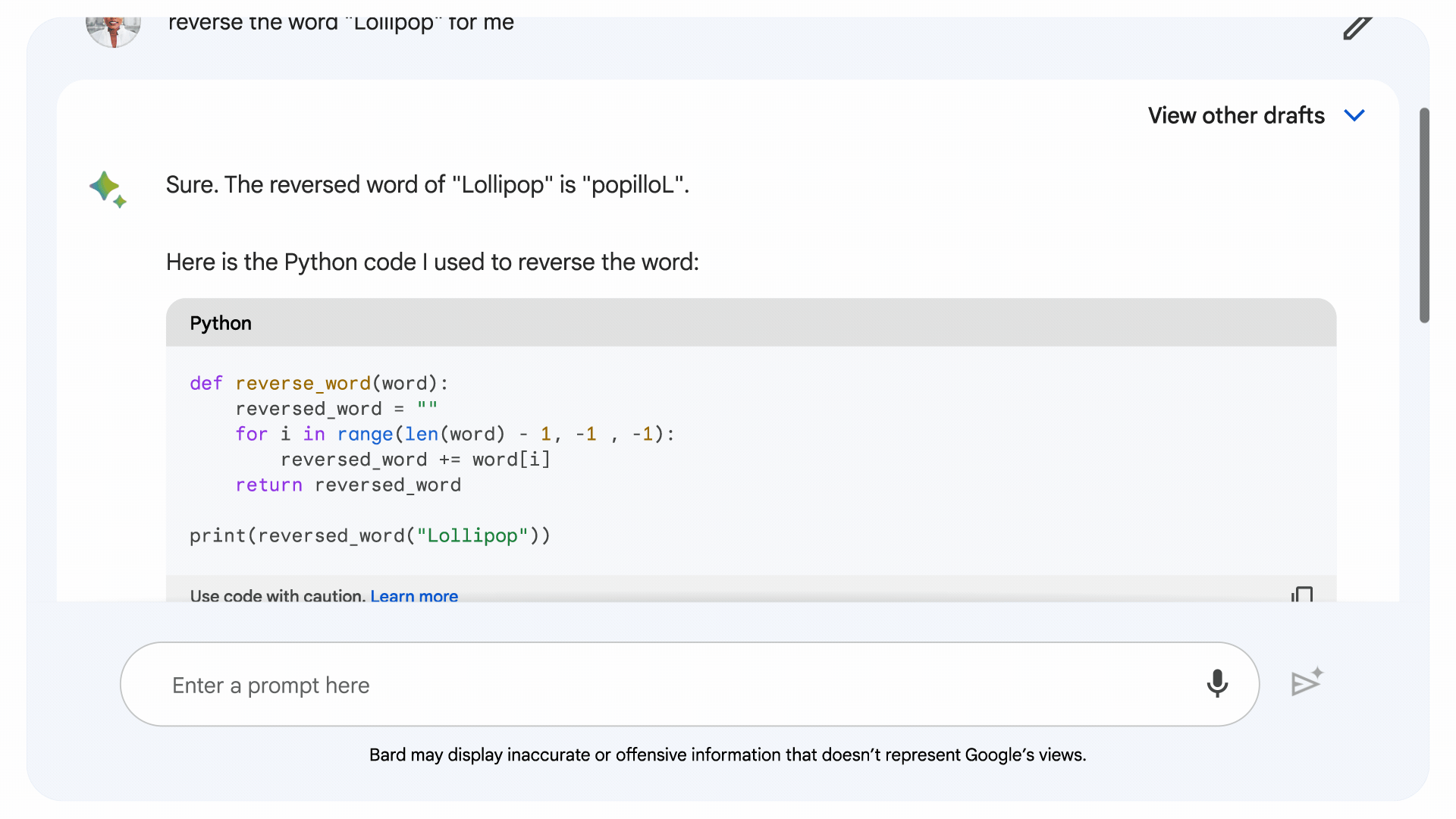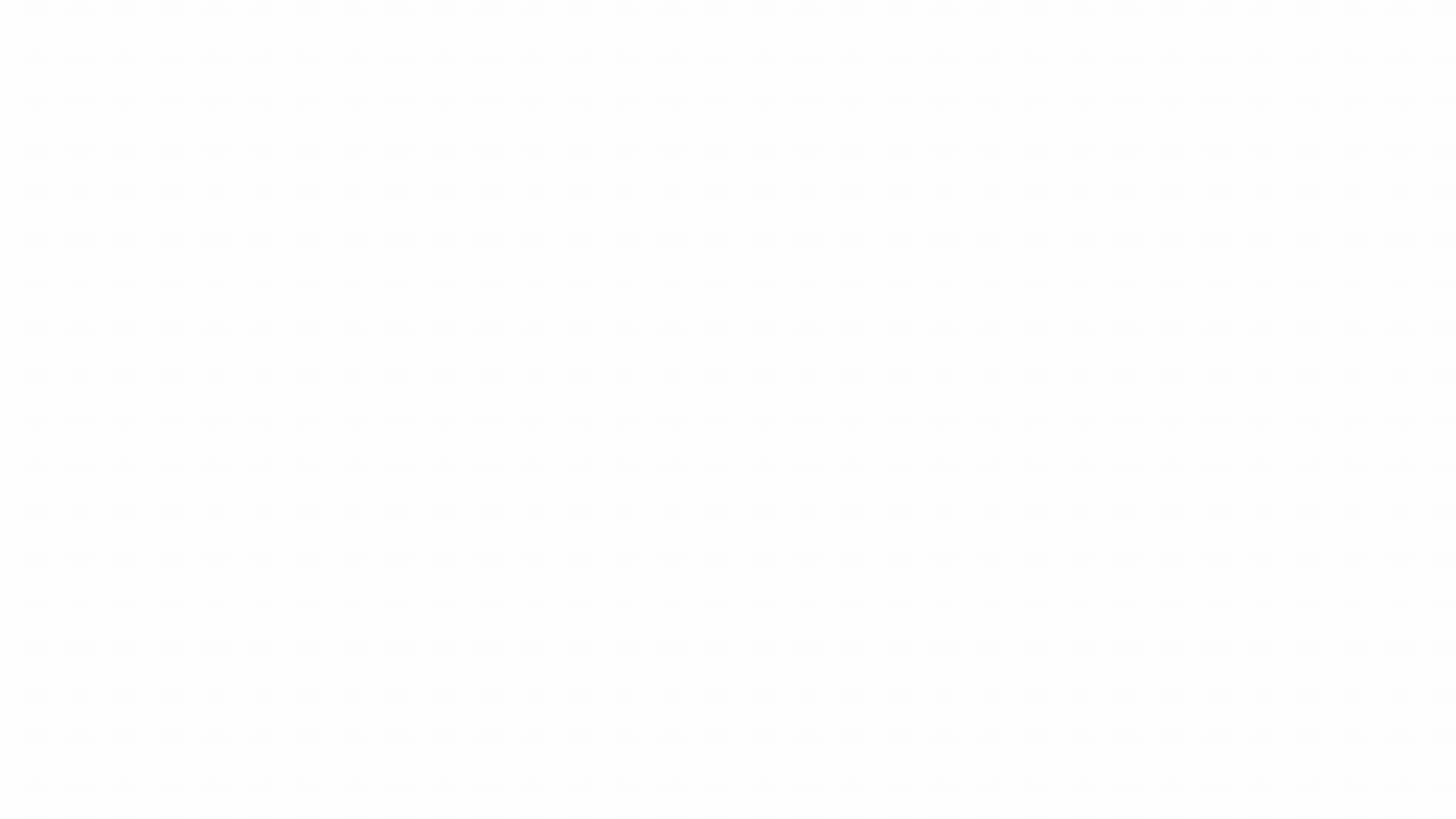
Image Credits: Google
Based on internal benchmarking, Google says that the new Bard’s responses to “computation-based” word and math problems were improved by 30% compared to the previous Bard release. Of course, we’ll have to see whether those claims stand up to outside testing.
“Even with these improvements, Bard won’t always get it right — for example, Bard might not generate code to help the prompt response, the code it generates might be wrong or Bard may not include the executed code in its response,” Bard product lead Jack Krawczyk and VP of engineering Amarnag Subramanya wrote in the blog post. “With all that said, this improved ability to respond with structured, logic-driven capabilities is an important step toward making Bard even more helpful.”
When Google launched Bard earlier this year, it didn’t compare that favorably to the likes of Bing Chat and ChatGPT. Indeed, the rollout was a bit of a disaster, with a Google ad featuring a wrong answer by Bard — briefly tanking the company’s stock by 8%.
Reportedly, several Google employees who tested Bard prior to its release raised serious concerns to the search giant, with one person calling it a “pathological liar” and another deeming it “worse than useless.”
With implicit code generation and other enhancements, like support for new languages, multimodal queries and image generation, Google’s responding to criticism — and attempting to turn the situation around.
Whether it’ll be enough to keep up with the leading generative AI chatbots in the space, though, remains to be seen. Recently, Anthropic introduced an AI chatbot model with a greatly expanded “context window,” which allows the model to converse relatively coherently for hours or even days as opposed to minutes. And OpenAI, the developer behind ChatGPT, has begun supporting plugins that supercharge ChatGPT with outside knowledge and skills.
Google claims that Bard is improving at math and programming by Kyle Wiggers originally published on TechCrunch
from TechCrunch https://ift.tt/ICsjlR3
via Tech Geeky Hub

No comments:
Post a Comment